
طراحی وب سایت بدون جدول چیست و چه مفهومی دارد؟
آبان ۲۰, ۱۳۹۶
آموزش تبدیل و دانگرید ویندوز ۱۰ از نسخه Pro به Home
آبان ۲۰, ۱۳۹۶
یادگیری ماشین شاخه ای از علوم کامپیوتر است که بدون انجام برنامه نویسی صریح، به کامپیوتر توانایی یادگیری می بخشد.
یادگیری ماشین
آرتور ساموئل (Arthur Samuel) امریکایی، یکی از پیشروهای حوزه بازی های کامپیوتری و هوش مصنوعی، عبارت “یادگیری ماشین” را در سال 1959 که در IBM کار می کرد، به ثبت رساند. یادگیری ماشین، که از اُلگوشناسی و نظریه یادگیری محاسباتی الهام گرفته شده است، مطالعه و ساخت الگوریتم هایی را که می توانند بر اساس داده ها یادگیری و پیش بینی انجام دهند بررسی می کند – چنین الگوریتم هایی از دستورات برنامه پیروی صرف نمی کنند و از طریق مدلسازی از داده های ورودی نمونه، پیش بینی یا تصمیم گیری می کنند. یادگیری ماشین در کارهای محاسباتی که طراحی و برنامه نویسی الگوریتم های صریح با عملکرد مناسب در آن ها سخت یا نشدنی است، استفاده می شود؛ برخی کاربردها عبارت اند از فیلترینگ ایمیل، شناسایی مزاحم های اینترنتی یا بدافزارهای داخلی که قصد ایجاد رخنه اطلاعاتی دارند، نویسه خوان نوری (OCR)، یادگیری رتبه بندی، و بینایی ماشین.
یادگیری ماشین ارتباط نزدیکی با آمار محاسباتی دارد (و اغلب با آن هم پوشانی دارد)، تمرکز این شاخه نیز پیش بینی کردن توسط رایانه است و پیوند محمکی با بهینه سازی ریاضی دارد، که آن هم روش ها، تئوری ها و کاربردهایی را وارد میدان می کند. یادگیری ماشین گاهی اوقات با داده کاوی ادغام می شود؛ تمرکز این زیرشاخه بر تحلیل اکتشافی داده ها است و با عنوان یادگیری بی نظارت شناخته می شود. یادگیری ماشین نیز می تواند بی نظارت باشد و برای یادگیری و شناخت فرم ابتدایی رفتار موجودات مختلف و سپس پیدا کردن ناهنجاری های معنادار استفاده شود.
در زمینه تحلیل داده ها، یادگیری ماشین روشی برای طراحی الگوریتم ها و مدل های پیچیده است که برای پیش بینی استفاده می شوند؛ در صنعت این مطلب تحت عنوان تحلیل پیشگویانه شناخته می شود. این مدل های تحلیلی به محققان، پژوهشگران علم داده ها، مهندسان و تحلیلگران اجازه می دهد “تصمیمات و نتایجی قابل اطمینان و تکرارپذیر بدست آورند” و با یادگیری از روابط و روندهای مربوط به گذشته، از “فراست های پنهان” پرده برداری کنند.
طبق سیکل هایپ (hype cycle) 2016 کمپانی گارتنر، یادگیری ماشین اکنون در مرحله “اوج توقعات زیاد (Peak of Inflated Expectations)” قرار دارد. پیاده سازی اثربخش یادگیری ماشین سخت است زیرا الگویابی دشوار است و اغلب، داده های آموزشی به مقدار کافی در دسترس نیست، در نتیجه برنامه های یادگیری ماشین اغلب با شکست مواجه می شوند.
نگاه کلی به یادگیری ماشین
تام ام. میچل (Tom M. Mitchell) تعریفی پر کاربرد و صوری از الگوریتم های مورد مطالعه در حوزه یادگیری ماشین ارائه نمود: “گوییم یک برنامه کامپیوتری از تجربه E نسبت به یک کلاس T از کارها و اندازه عملکرد P، یاد گرفته است، هرگاه با داشتن تجربه E عملکرد آن که توسط P اندازه گیری می شود در کارهای کلاس T بهبود یافته باشد.” این تعریف از کارهایی که یادگیری ماشین درگیر آن است، تعریفی کاملاً اجرایی است و نه صرفاً تعریفی شناختی. این تعریف دنباله رو پروپزال آلن تورینگ (Alan Turing) در مقاله او “هوش و ماشین محاسبه گر” است که در آن، سوال “آیا ماشین ها می توانند فکر کنند؟” با سوال “آیا ماشین ها می توانند کاری را انجام دهند که ما (به عنوان موجودات متفکر) می توانیم انجام دهیم؟” جایگزین شد. در مقاله تورینگ، ویژگی های متنوعی که یک ماشین متفکر می تواند داشته باشد، و نتایج ساختن چنین ماشینی بررسی شده است.
انواع مسائل و کارها
کارهای (وظایف) یاد گیری ماشین معمولا به دو دسته وسیع تقسیم می شوند؛ بسته به این که در یک سیستم یادگیری “فیدبک” یا “سیگنال” یادگیری وجود داشته باشد یا خیر:
- یادگیری با نظارت: یک “معلم” به کامپیوتر ورودی های مثال و خروجی های مطلوب هر یک را می دهد، و هدف، یادگیری یک قانون کلی است که ورودی ها را به خروجی ببرد. در حالت های خاص، سیگنال ورودی ممکن است تنها بطور جزئی در دسترس باشد، یا به فیدبکی خاص محدود باشد.
- یادگیری نیمه نظارتی: به کامپیوتر تنها یک سیگنال آموزشی ناقص داده می شود: یک مجموعه آموزشی که بعضی (اغلب بسیاری) از خروجی های هدف آن غایب هستند.
- یادگیری فعال: کامپیوتر تنها می تواند برچسب های آموزشی را برای مجموعه ای محدود از نمونه ها بدست آورد ( بر اساس بودجه)، و همچنین باید انتخاب اشیاء را برای دستیابی به برچسب ها بهینه کند. هنگام استفاده تعاملی، این موارد برای برچسب گذاری قابل ارائه به کاربر هستند.
- یادگیری تقویتی: داده آموزشی (به شکل پاداش یا تنبیه) به عنوان فیدبک به فعالیت های برنامه تنها در محیطی پویا داده می شود، مثل رانندگی ماشین یا بازی کردن در مقابل یک حریف.
- یادگیری بی نظارت: هیچ برچسبی به الگوریتم یادگیرنده داده نمی شود، و خود الگوریتم باید ساختاری در ورودی پیدا کند. یادگیری بی نظارت به خودی خود می تواند یک هدف (پیدا کردن الگوهای پنهان در داده)، یا وسیله ای برای رسیدن به یک هدف باشد (یادگیری نمایش).
در میان دسته های دیگر مسائل یادگیری ماشین، فرا یادگیری، اُریب استقرایی خود را بر مبنای تجربه پیشین یاد می گیرد. یادگیری رشدی که برای رباتیک ساخته و پرداخته شده است، خود شرایط یادگیری دنباله داری (که دوره تحصیلی نیز نام دارد) را تولید می کند تا مهارت های جدید را از طریق کاوش خود مختارانه و تعاملات اجتماعی با معلم های انسان و استفاده از مکانیزم های هدایتی از قبیل یادگیری فعال، بلوغ، هم افزایی حرکتی و تقلید، جمع آوری کند.
با در نظر گرفتن خروجی مطلوب یک سیستم یادگیری ماشین، دسته بندی دیگری از فعالیت های یادگیری ماشین به وجود می آید:
- در طبقه بندی آماری (classification)، ورودی ها را به دو یا چند طبقه تقسیم می کنند، و یادگیرنده باید مدلی تولید کند که ورودی های دیده نشده را به یک یا چند طبقه تخصیص دهد (طبقه بندی چند برچسبی). این مسئله معمولا به شکل نظارت شده حل می شود. فیلترینگ اسپم یکی از نمونه های طبقه بندی است، که در آن ورودی ها، پیام های ایمیل (یا هر پیام دیگری) و طبقه ها “اسپم” و “غیر اسپم” هستند.
- در رگرسیون که آن هم یک مسئله نظارت شده است، خروجی ها پیوسته هستند نه گسسته.
- در خوشه بندی، مجموعه ای از ورودی ها باید به چند گروه تقسیم شود. بر خلاف طبقه بندی آماری، گروه ها از قبل شناخته شده نیستند، چیزی که باعث می شود این فعالیت بی نظارت باشد.
- تخمین چگالی، توزیع ورودی ها را در یک فضا پیدا می کند.
کاهش بُعد، داده ها را با نگاشتن آن ها در فضایی با بعُد پایین تر، ساده سازی می کند. مدل سازی عناوین، یک مسئله مرتبط است، که در آن به برنامه فهرستی از اسناد به زبان انسان داده می شود و ماموریت برنامه این است که کشف کند کدام اسناد موضوعات مشابهی دارند.
تاریخچه یادگیری ماشین و ارتباط با سایر رشته ها
یادگیری ماشین از حوزه هوش مصنوعی فراتر است. در همان روزهای ابتدایی ایجاد هوش مصنوعی به عنوان رشته ای علمی، برخی محققان در پی این بودند که ماشین ها از داده ها یادگیری کنند. آن ها تلاش کردند این مسئله را با روش های نمادین متنوعی، و نیز چیزی که آن موقع “شبکه های عصبی” نام داشت، حل کنند؛ این روش ها اغلب پرسپترون (perceptron) و مدل های دیگری بودند که بَعد ها مشخص شد بازطراحی مدل های خطی تعمیم یافته آماری بوده اند. استدلال احتمالاتی، به ویژه در تشخیص پزشکی مکانیزه، مورد استفاده قرار گرفت.
با این حال، تاکید روز افزون بر روش منطقی و دانش-محور، شکافی بین AI (هوش مصنوعی) و یادگیری ماشین ایجاد کرد. سیستم های احتمالاتی پُر شده بودند از مسائل تئوری و عَمَلی در مورد بدست آوردن و نمایش داده ها. تا سال 1980، سیستم های خِبره بر AI رجحان یافتند و آمار دیگر مورد توجه نبود. کار بر روی یادگیری نمادین/دانش-محور، درون حیطه AI ادامه پیدا کرد و به برنامه نویسی منطقی استقرایی منجر شد، اما سِیر آماری پژوهش دیگر از حیطه AI صِرف خارج شده بود و در الگوشناسی و بازیابی اطلاعات دیده می شد. پژوهش در زمینه شبکه های عصبی نیز حدود همین زمان توسط AI و علوم کامپیوتر (CS) طَرد شد. این مسیر نیز خارج از حوزه AI/CS توسط محققان رشته های دیگر از جمله هاپفیلد (Hopfield)، راملهارت (Rumelhart) و هینتون (Hinton) تحت عنوان پیوندگرایی (connectionism) دنبال شد. موفقیت عمده آن ها در اواسط دهه 1980 با بازتولید پَس نشر (backpropogation) حاصل شد.
یادگیری ماشین، پس از احیا به عنوان رشته ای مجزا، در دهه 1990 شروع به درخشش کرد. این رشته هدف خود را از دستیابی به هوش مصنوعی، به درگیر شدن با مسائل حل پذیری که طبیعتی عَملی دارند، تغییر داد و تمرکز خود را از روش های نمادینی که از هوش مصنوعی به ارث برده بود، به روش ها و مدل هایی که از آمار و احتمالات قرض گرفته بود، انتقال داد. این رشته همچنین از اطلاعات دیجیتالی که روز به روز دسترس پذیر تر می شدند و از امکان توزیع آن ها در اینترت، بهره برد.
یادگیری ماشین و داده کاوی اغلب از روش های یکسانی بهره می برند و با یکدیگر همپوشانی چشمگیری دارند، اما در حالی که یادگیری ماشین بر پیش بینی بر مبنای خواصِ معلومِ یادگرفته شده از داده های آموزش تمرکز دارد، داده کاوی روی کشف خواص (سابقاً) نامعلوم در داده ها تمرکز می کند (این عمل، مرحله تحلیل استخراج دانش در پایگاه داده هاست). داده کاوی از روش های یادگیری ماشین متعددی استفاه می کند اما با اهداف متفاوت؛ از طرف دیگر یادگیری ماشین نیز از روش های داده کاوی به عنوان “یادگیری بدون نظارت” یا به عنوان مرحله پیش پردازش برای بهبود دقت یادگیرنده استفاده می کند. بیشتر سردرگمی های میان این دو رشته پژوهشی (که اغلب کنفرانس ها و مجلات متمایزی دارند، به استثنای ECML PKDD) از فرضیات بنیادینی که دارند نشئت می گیرد: در یادگیری ماشین، عملکرد را معمولاً با توانایی بازتولید دانش معلوم ارزیابی می کنند، در حالی که در استخراج دانش و داده کاوی (KDD)، فعالیت کلیدی، کشف دانشی است که قبلا ناشناخته بوده است. در مقایسه با دانش معلوم، یک روش بی نظارت (یک روش بی اطلاع) به راحتی از سایر روش های نظارت شده شکست می خورد، در حالیکه در یک فعالیت معمولی KDD، روش های نظارت شده به دلیل عدم دسترسی به داده های آموزشی، قابل استفاده نیستند.
یادگیری ماشین همچنین ارتباط تنگاتنگی با بهینه سازی دارد: بسیاری از مسائل یادگیری به شکل مینیمم سازی یک تابع زیان روی یک مجموعه از مثال های آموزشی بیان می شوند. توابع زیان، بیان کننده اختلاف بین پیش بینی های مدلِ تحت یادگیری و شواهد واقعی مسئله هستند (برای مثال، در طبقه بندی، هدف تخصیص برچسب به شواهد است، و به مدل ها آموزش داده می شود تا قبل از تخصیص، برچسب های یک مجموعه از مثال ها را پیش بینی کنند). تفاوت میان این دو رشته، از هدف کلان آن ها نشئت می گیرد: در حالیکه الگوریتم های بهینه سازی می توانند زیان را روی یک مجموعه آموزشی کمینه کنند، یادگیری ماشین می خواهد زیان را روی نمونه های مشاهده نشده کمینه کند.
ارتباط یادگیری ماشین با آمار
یادگیری ماشین و آمار رشته های نزدیکی هستند. طبق نظر مایکل. ال. جردن (Micheal l. Jordan) ایده های یادگیری ماشین، از اصول متدلوژی گرفته تا ابزار نظری، پیشینه ای طولانی در آمار دارند. او همچنین عبارت علم داده ها را برای نام گذاری کل این رشته پیشنهاد کرد.
لئو بریمن (Leo Breiman) دو پارادایم آماری را مطرح ساخت: مدل داده و مدل الگوریتمیک، که مدل “الگوریتمیک” کما بیش به معنای الگوریتم های یادگیری ماشین مثل جنگل تصادفی است.
برخی آماردانان با استفاده از روش های یادگیری ماشین، گرایشی ساخته اند که آن را یادگیری آماری می نامند.
تئوری یادگیری ماشین
یک هدف اساسی ماشین یادگیرنده، تعمیم دهی از تجربه است. منظور از تعمیم دهی در این چهارچوب، توانایی یک ماشین یادگیرنده در داشتن عملکردی دقیق در فعالیت ها و مثال های جدید و دیده نشده، بر مبنای تجربه آن ماشین با مجموعه داده های آموزش است. مثال های آموزشی از یک توزیعِ عموماً ناشناخته می آیند (که به عنوان نماینده فضای رخدادها در نظر گرفته می شود) و یادگیرنده باید برای این فضا مدلی عمومی تولید کندکه به آن، توانایی پیش بینیِ بقدر کافی دقیق در موارد جدید را بدهد.
تحلیل محاسباتی الگوریتم های یادگیری ماشین و عملکرد آن ها شاخه ای از علوم کامپیوتر نظری تحت عنوان نظریه یادگیری محاسباتی را تشکیل می دهد. چون مجموعه های داده های آموزشی، متناهی هستند و آینده قطعیت ندارد، نظریه یادگیری معمولا تضمینی در مورد عملکرد الگوریتم ها به ما نمی دهد. در عوض، کران های احتمالاتی روی عملکرد، بسیار معمول هستند. تجزیه اُریب-واریانس (bias-variance decomposition) راهی برای کمّی سازی خطای تعمیم دهی است.
برای داشتن بهترین عملکرد در چهارچوب تعمیم دهی، پیچیدگی فرض باید به اندازه پیچیدگی تابع زمینه داده ها باشد. اگر فرض پیچیدگی کمتری از تابع داشته باشد، آنگاه مدل، داده ها را زیربرازش (underfit) کرده است. اگر در پاسخ، پیچیدگی مدل افزایش یابد، آنگاه خطای آموزش کاهش می یابد. اما اگر فرض بسیار پیچیده باشد، مدل در معرض بیش برازش (overfit)قرار می گیرد و تعمیم دهی ضعیف می شود.
علاوه بر کران های عملکردی، نظریه پردازان یادگیری محاسباتی، پیچیدگی زمانی و امکان پذیری یادگیری را نیز مطالعه می کنند. در نظریه یادگیری محاسباتی، یک محاسبه را امکان پذیر نامند هرگاه در زمان چند جمله ای قابل انجام باشد. دو نوع نتیجه از نظر پیچیدگی زمانی وجود دارد: نتایج مثبت حاکی از آن هستند که طبقه خاصی از توابع در زمان چند جمله ای قابل یادگیری هستند و نتایج منفی نشانگر این هستند که طبقه های خاصی در زمان چند جمله ای قابل یادگیری نیستند.
روش های یادگیری ماشین
یادگیری درخت تصمیم یا Decision tree learning
روش یادگیری درخت تصمیم از یک درخت تصمیم به عنوان مدل پیشگو استفاده می کند که مشاهدات در مورد یک شیء را به نتایجی در مورد ارزش هدف این شی می نگارد.
یادگیری قانون وابستگی
یادگیری قانون وابستگی روشی برای کشف روابط جالب توجه میان متغیرها در پایگاه های بزرگ داده است.
شبکه های عصبی مصنوعی
یک الگوریتم شبکه عصبی مصنوعی (ANN)، که معمولا “شبکه عصبی” (NN) نامیده می شود، الگوریتمی است که از ساختار و جنبه های عملکردی شبکه های عصبی بیولوژیکی الهام گرفته شده است. در این شبکه، محاسبات در قالب گروه های متصلی از نورون های مصنوعی، ساختار می یابند و اطلاعات را با یک روش پیوندگرایی به محاسبات، پردازش می کند. شبکه های عصبی مدرن، ابزارهای مدل سازی غیر خطی داده های آماری هستند. این شبکه ها معمولا برای مدل سازی روابط پیچیده بین ورودی ها و خروجی ها، الگو شناسی در داده ها، یا دریافت ساختار آماری در یک توزیع توئم احتمال میان متغیر های مشاهده شده استفاده می شوند.
یادگیری عمیق
کاهش قیمت سخت افزار و تولید GPU برای مصرف شخصی در سال های اخیر به توسعه مفهوم یادگیری عمیق که از چندین لایه پنهان در یک شبکه عصبی مصنوعی تشکیل می شود، کمک کرده است. این روش سعی دارد راهی را که با آن، مغز انسان، نور و صوت را به بینایی و شنوایی پردازش می کند، مدل سازی نماید. برخی از کاربردهای موفق یادگیری عمیق، بینایی ماشین و شناسایی گفتار است.
برنامه نویسی منطقی استقرایی
برنامه نویسی منطقی استقرایی (ILP) روشی برای هدایت یادگیری با استفاده از برنامه نویسی منطقی به عنوان نمایشی یکنواخت برای مثال ها (داده ها)ی ورودی، دانش پس زمینه و فرضیات است. با داشتن یک کدگذاری (encoding) از دانشِ معلومِ پس زمینه و مجموعه ای از مثال ها که به عنوان پایگاه داده ای از حقایق نمایش داده می شود، یک سیستم ILP برنامه ای منطقی استخراج می کند که تمام مثال های مثبت را نتیجه دهد و هیچ یک از مثال های منفی را نتیجه ندهد. برنامه نویسی استقرایی (inductive programming) شاخه ای مرتبط است که هر نوع زبان برنامه نویسی برای نمایش فرضیات را در بر می گیرد (و نه فقط برنامه نویسی منطقی)، از قبیل برنامه های تابعی.
ماشین های بُردار پشتیبانی
ماشین های بردار پشیتیبانی (SVM) مجموعه ای از روش های یادگیری نظارت شده ی مرتبطی هستند که برای طبقه بندی و رگرسیون استفاده می شوند. با داشتن مجموعه ای از مثال های آموزشی که هر کدام به عنوان عضوی از یکی از دو دسته فوق علامت گذاری شده اند، الگوریتم آموزشی SVM مدلی می سازد که پیش بینی می کند یک مثال جدید به کدام دسته تعلق خواهد گرفت.
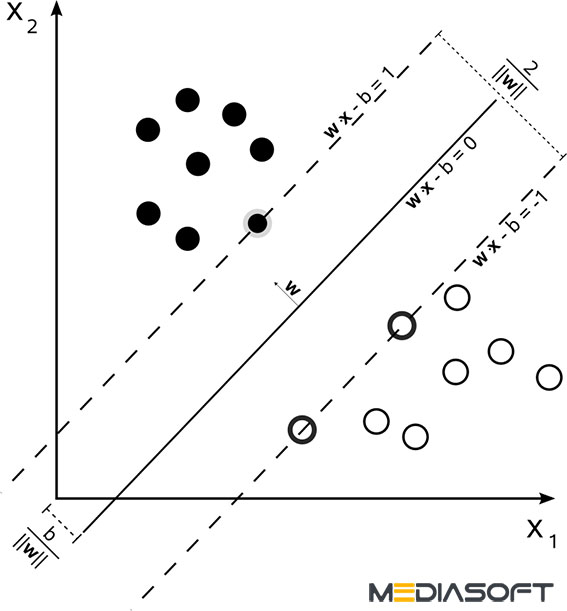
ماشین بردار پشتیبانی، دسته ساز (طبقه سازی) است که فضای ورودی خود را به دو ناحیه تقسیم می کند، که توسط یک مرز خطی از هم جدا شده اند. در این مثال، ماشین یاد گرفته است که دایره های سفید و سیاه را از هم جدا کند.
خوشه بندی یا Clustering
تحلیل خوشه ای به معنای تخصیص مجموعه ای از مشاهدات به زیرمجموعه هایی (به نام خوشه) است بطوریکه مشاهداتِ درون یک خوشه، بنابر معیار یا معیارهایی از پیش تعیین شده، شبیه باشند و مشاهداتی که در خوشه های مختلف قرار دارند، بی شباهت باشند. تکنیک های خوشه بندی متفاوت، روی ساختار داده ها فرضیات متفاوتی دارند، که اغلب توسط یک متریک تشابه تعریف می شوند و، به عنوان مثال، توسط فشردگی درونی (تشابه بین اعضای درون یک خوشه) و جدایی بین خوشه های مختلف ارزیابی می شوند. روش های دیگر مبتنی بر چگالی تخمینی و همبندی گراف می باشند. خوشه بندی یک روش یادگیری بی نظارت، و تکنیکی متداول برای تحلیل داده های آماری است.
شبکه های بِیزی یا Bayesian networks
شبکه بیزی، شبکه باور (belief network) یا مدل گراف جهتدار غیرمدور، یک مدل گرافی احتمالاتی است که مجموعه متغیرهای تصادفی و استقلال شرطی آن ها را توسط یک گراف جهتدار غیرمدور (DAG) نمایش می دهد. برای مثال، شبکه بیزی می تواند ارتباط های احتمالاتی میان بیماری ها و علائم بیماری را نمایش دهد. با داشتن علائم، شبکه می تواند احتمال وجود بیماری های مختلف را محاسبه کند. الگوریتم های اثربخشی وجود دارند که استنباط و یادگیری را انجام می دهند.
یادگیری تقویتی
تمرکز روش یادگیری تقویتی بر این است که یک عامل چگونه باید در یک محیط عمل کند تا نوعی پاداش بلند مدت را بیشینه کند. الگوریتم های یادگیری تقویتی سعی دارند قاعده ای پیدا کنند که وضعیت های جهان را به عمل هایی که عامل باید در این وضعیت ها انجام دهد، تصویر کند. تفاوت یادگیری تقویتی با یادگیری نظارت شده در این است که جفت های صحیح وردودی/خروجی هرگز ارائه نمی شوند و نیز فعالیت های زیر-بهین (sub-optimal) نیز صریحاً اصلاح نمی شوند.
یادگیری نمایش یا Representation learning
هدف برخی الگوریتم های یادگیری، عمدتاً الگورییم های یادگیری بدون نظارت، این است که نمایش بهتری برای ورودی های ارائه شده در آموزش پیدا کنند. مثال های کلاسیک در این زمینه، تحلیل مولفه های اصلی و تحلیل خوشه ای هستند. الگوریتم های یادگیری نمایش اغلب سعی در حفظ اطلاعات در ورودی ها دارند اما می خواهند آن را به شکلی تبدیل کنند که ورودی سودمند شود، که اغلب این عمل در مرحله پیش پردازش قبل از طبقه بندی یا پیش بینی انجام می شود، و امکان بازسازی ورودی ها را که از یک توزیعِ ناشناختهِ مولدِ داده می آیند فراهم می کند، در حالیکه لزوماً به ویژگی هایی که تحت این توزیع نامحتمل هستند، وفادار نمی ماند.
الگوریتم های یادگیری منیفلد (Manifold learning) سعی دارند همین کار را با این محدودیت که نمایش یادگیری شده بُعد پایینی دارد، انجام دهند. الگوریتم های کدگذاری تُنُک سعی دارند همین کار را با این محدودیت که نمایش یادگیری شده تنک است (یعنی صفرهای زیادی دارد)، انجام دهند. الگوریتم های یادگیری زیرفضای چندخطی سعی دارند نمایش های با بُعد پایین را مستقیماً از نمایش های تانسوری داده های چند بعدی، بدون دادن شکل بُرداری (بعد بالا) به آن ها، یادگیری کنند. الگوریتم های یادگیری عمیق، چندین سطح نمایش، یا سلسله ای از ویژگی ها را کشف می کنند، که ویژگی های سطح بالاتر و انتزاعی تر، بر حسب ویژگی های سطح پایین تر تعریف شده اند (یا آن ها را تولید می کنند). استدلال شده است که یک ماشین هوشمند ماشینی است که نمایشی را یاد می گیرد که فاکتورهای اساسی تغییرات را که داده های مشاهده شده را توضیح می دهند، تمییز دهد.
یادگیری تشابه و متریک
در این مسئله، به ماشین یادگیرنده جفت های مثالی که مشابه در نظر گرفته شده اند، و جفت هایی که تشابه کمتری دارند، داده می شود. سپس ماشین باید یک تابع تشابه (یا یک تابع فاصله متریک) را یاد بگیرد که پیش بینی کند آیا اشیاء جدید شبیه هستند یا خیر. این روش برخی اوقات در سیستم های توصیه گر استفاده می شود.
یادگیری دیکشنری تُنُک یا Sparse dictionary learning
در این روش، یک داده به شکل ترکیبی خطی از توابع پایه ای نمایش داده می شود، و فرض می شود که ضرایب این ترکیب تنک هستند. فرض کنید که x یک داده d بُعدی و D یک ماتریس d در n باشد که هر ستون آن نمایشگر یک تابع پایه ای است. r ضریب نمایش x با استفاده از D است. از نظر ریاضی، یادگیری دیکشنری تنک به معنی حل دستگاه x ≈ Dr است که در آن r تنک است. بطور کلی n از d بزرگ تر فرض می شود تا آزادی برای نمایش تنک فراهم شود.
یادگیری دیکشنری با نمایش های تُنُک “ان-پی کاملِ قوی” (strongly NP-hard) است و حل تقریبی آن هم دشوار است. یک روش ابتکاری محبوب برای یادگیری دیکشنری تنک K-SVD است.
یادگیری دیکشنری تنک در چندین چهارچوب مورد استفاده قرار گرفته است. در طبقه بندی، مسئله، تعیین کلاسی است که داده ای که قبلا ناشناخته بوده، به آن تعلق دارد. فرض کنید که قبلاً یک دیشکنری برای هر کلاس ساخته شده است. آنگاه یک داده جدید به کلاسی مرتبط می شود که دیکشنری آن کلاس بهترین نمایش تنک برای آن داده را بدست دهد. یادگیری دیکشنری تنک در کاهش نویز تصویر نیز استفاده شده است. ایده کلیدی این است که یک تصویر “تمیز” را می توان به شکل تنک توسط یک دیکشنریِ تصویر نمایش داد، اما نویز را نمی توان.
الگوریتم های ژنتیک
یک الگوریتم ژنتیک (GA)، الگورریتم جستجوی ابتکاری است که از فرایند انتخاب طبیعی تقلید می کند، و به امید یافتن پاسخ های مناسب به یک مسئله، ازروش های مثل جهش (mutation) و دوتیرگی (crossover) برای تولید کروموزوم جدید، استفاده می کند. در یادگیری ماشین، الگوریتم های ژنتیک در دهه های 1980 و 1990 کاربرد یافتند. برعکس، تکنیک های یادگیری ماشین نیز برای بهبود عملکرد الگوریتم های تکاملی و ژنتیک مورد استفاده قرار گرفته اند.
یادگیری ماشین قانون-محور
یادگیری ماشین قانون-محور عبارتی کلی برای هر نوع روش یادگیری ماشینی است که برای ذخیره، کنترل یا استفاده از دانش، “قوانینی” را شناسایی، یادگیری یا استنتاج می کند. ویژگی مشخصه یک ماشین یادگیرنده قانون-محور، شناسایی و استفاده از مجموعه ای از قوانین است که بطور جمعی، نمایشگر دانش فراگرفته شده توسط سیستم هستند. این روش، با سایر یادگیرنده های ماشینی که عموماً یک مدل واحد را در تمام موارد برای پیشگویی می شناسند، در تمایز است. روش های یادگیری ماشین قانون-محور شامل سیستم های طبقه ساز یادگیرنده، یادگیری قانون وابستگی و سیستم های ایمنی مصنوعی هستند.
سیستم های طبقه ساز یادگیرنده Learning classifier systems
سیستم های طبقه ساز یادگیرنده یا به عبارتی طبقه بندی کننده ی یادگیرنده (LCS)، خانواده ای از الگوریتم های قانون-محور یادگیری ماشین هستند که یک مولفه اکتشاف (مثلاً بطور معمول یک الگوریتم ژنتیک) را یا یک مولفه یادگیرنده (که یادگیری نظارتی، یادگیری تقویتی یا یادگیری بی نظارت را انجام می دهد) ترکیب می کنند. هدف این سیستم ها شناسایی مجموعه ای از قوانین وابسته به موضوع است که بطور جمعی، دانش را ذخیره و برای پیش بینی ها آن را به شکلی چند ضابطه ای استفاده می کنند.
کاربردهای یادگیری ماشین
کاربردهای یادگیری ماشین شامل موارد زیر است:
- اثبات قضیه بطور خودکار
- وبسایت های تطبیقی
- هوش مصنوعی احساسی
- بیوانفوماتیک
- واسط مغز و رایانه
- شیمی انفورماتیک
- طبقه بندی رشته های DNA
- آناتومی محاسباتی
- بینایی ماشین، از جمله شناسایی اشیاء
- شناسایی کارت اعتباری جعلی
- بازی عمومی (general game playing)
- بازیابی اطلاعات
- شناسایی کلاه برداری های اینترنتی
- زبان شناسی
- بازاریابی
- کنترل یادگیری ماشین
- ادراک ماشین
- تشخیص پژشکی
- اقتصاد
- بیمه
- پردازش زبان طبیعی
- استنباط زبان طبیعی
- بهینه سازی و الگوریتم های فرا ابتکاری
- تبلیغات آنلاین
- سیستم های توصیه گر
- حرکت ربات
- موتورهای جستجو
- تحلیل احساسات (یا نظر کاوی)
- مهندسی نرم افزار
- شناسایی گفتار و دست نوشته
- تحلیل بازارهای مالی
- نظارت بر درستی ساحتار
- الگوشناسی ترکیبی
- پیش بینی سری های زمانی
- تحلیل رفتار کاربر
- ترجمه
در سال 2006 کمپانی فیلم سازی آنلاین نتفلیکس اولین رقابت “جایزه نتفلیکس” را برگزار کرد تا برنامه ای پیدا کند که پیش بینی بهتری از تمایلات کاربر داشته و دقت الگوریتم فعلی توصیه فیلم (Cinematch) خود را لااقل 10% بهبود بخشد. گروهی متشکل از محققان بخش تحقیق و آزمایشگاه AT&T
به همراه تیم های Big Chaos و Pragmatic Theory یک مدل چندگانه (ensemble model) ساختند که برنده جایزه 1 میلیون دلاری سال 2009 شد.
اندکی بعد از اهدای جایزه، نتفلیکس متوجه شد که امتیازدهی بینندگان، بهترین شاخص برای الگوی تماشای آن ها نیست (“همه چیز یک توصیه است”) و بنابراین موتو توصیه گر خود را تغییر دادند.
در سال 2010 وال استریت ژورنال مقاله ای راجع به شرکت Rebellion Research و استفاده آن ها از یادگیری ماشین برای پیش بینی بحران مالی نوشت.
در سال 2012، وینود کسلا (Vinod Khosla) یکی از موسسین سان مایکروسیستمز (Sun Microsystems)، پیش بینی کرد که در دو دهه آینده بیش از 80% از فرصت های شغلی پزشکی توسط نرم افزارهای تشخیص پزشکی یادگیری ماشین از بین خواهد رفت.
در سال 2014، گزارش شد که یک الگوریتم یادگیری ماشین در مطالعه تاریخ هنر استفاده شد تا نقاشی های هنرهای زیبا را بررسی کند، و نیز گزارش شد که این الگوریتم ممکن است تاثیرگذاری هایی را میان هنرمندان نشان داده باشد که قبلا شناخته شده نبوده است.
ارزیابی مدل
مدل های یادگیری ماشین طبقه بندی را می توان با تکنیک های تخمین دقت مثل روش هولد اوت (holdout) که داده ها را به یک مجموعه آموزش و یک مجموعه آزمایش تقسیم می کند (معمولا دو-سوم داده ها در مجموعه آموزش و یک-سوم را در مجموعه آزمایش قرار می گیرند) و عملکرد مدل تحت آموزش را روی مجموعه آزمایش ارزیابی می کند، راستی آزمایی نمود. در مقایسه، روش تصدیق متقاطع N تایی (N-fold cross validation) بطور تصادفی داده ها را به k زیرمجموعه تقسیم می کند که k-1 مورد از داده ها برای آموزش مدل استفاده می شود و k-اُمین مورد برای آزمایش توانایی پیشگویی مدل استفاده می شود. علاوه بر روش های holdout و تصدیق متقاطع، راه اندازی خودکار (booststrap) که n مورد را، با جایگذاری، از مجموعه داده ها نمونه گیری می کند، می تواند برای ارزیابی دقیق مدل استفاه شود.
محققان علاوه بر دقت کلی، اغلب حساسیت و ویژگی را، که به ترتیب به معنای نسبت مثبت واقعی (TPR) و نسبت منفی واقعی (TNP) هستند، گزارش می کنند. بطور مشابه، محققین برخی اوقات نسبت مثبت کاذب (FPR) و نسبت منفی کاذب (FNR) را نیز گزارش می کنند. با این حال، این ها نسبت هایی هستند که صورت و مخرج خود را نشان نمی دهند. مشخصه عملگری کل (TOC) روشی موثر جهت بیان توانایی تشخیص یک مدل است. TOC صورت و مخرج نسبت های فوق را نمایش می دهد، لذا اطلاعات بیشتری از منحنی های معمول مشخصه عملیاتی سیستم (ROC) و مساحت زیر این منحنی (AUC) بدست می دهد.
مسائل اخلاقی
یادگیری ماشین پرسش های اخلاقی متعددی را بوجود می آورد. سیستم های آموزش دیده روی مجموعه های داده های اُریب یا بایاس (bias) ، ممکن است این اریبی ها را هنگام استفاده نمایش دهند، لذا تبعیضات فرهنگی را دیجیتالی کنند. بنابراین جمع آوری مسئولانه داده ها بخش مهمی از یادگیری ماشین است.
چون زبان دارای اریبی است، ماشین هایی که روی پیکره های زبان (language coropa) آموزش داده شده اند لزوماً اریبی را نیز یاد می گیرند.
نرم افزارها
برخی بسته های نرم افزاری که الگوریتم های یادگیری ماشین متنوعی دارند به شرح زیر هستند:
نرم فزار های رایگان و متن باز:
CNTK
Deeplearning4j
dlib
ELKI
GNU Octave
H2O
Mahout
Mallet
MEPX
mlpy
MLPACK
MOA (Massive Online Analysis)
MXNet
ND4J: ND arrays for Java
NuPIC
OpenAI Gym
OpenAI Universe
OpenNN
Orange
R
scikit-learn
Shogun
TensorFlow
Torch
Yooreeka
Weka
نرم افزارهای مالکیتی با ویرایش های رایگان و متن باز:
KNIME
RapidMiner
نرم افزار های مالکیتی:
Amazon Machine Learning
Angoss KnowledgeSTUDIO
Ayasdi
IBM Data Science Experience
Google Prediction API
IBM SPSS Modeler
KXEN Modeler
LIONsolver
Mathematica
MATLAB
Microsoft Azure Machine Learning
Neural Designer
NeuroSolutions
Oracle Data Mining
RCASE
SAP Leonardo
SAS Enterprise Miner
SequenceL
Skymind
Splunk
STATISTICA Data Miner
ژورنال ها
Journal of Machine Learning Research
Machine Learning
Neural Computation



{kind=link}
130 Comments
باتشکر از مطلب خوب شما
لطفا آنرا برای اینجانب ارسال نمایید.
باتشکر
با عرض سلام و احترام و تشکر بابت نظر شما
مقاله ارسال شد.
سلام ممنون بابت مطالب مفید درج شده ،اگر امکانش هست ممنون میشم برای من هم ارسال کنید
با عرض سلام و احترام و تشکر بابت نظر لطف شما؛
مقاله ارسال شد.
سلام و عرض ادب
لطفا اگر مقاله ای در جهت یادگیری بیشتر دارید به ایمیل من بفرستید
با سپاس
اگه ممکن باشه مقاله رو برأی من بفرستید
با عرض سلام و احترام
مقاله ارسال شد.
سلام ببخشید امکانش هست مطالب مربوط به یادگیری ماشین رو برام ارسال کنید.ممنون
سلام و عرض احترام
مقاله ارسال شد.
سلام و روز بخیر
من در طی یک فعالیت در رابطه با یک مقاله به مطالب شما در مورد یادگیری ماشین احتیاج دارم . ممنون میشم اگر فایل مقاله را برایم ارسال کنید چون که حداقل به منابع استخراج شده ان جهت ثبت یک سری از مطالب نیاز دارم . ممنونم
با عرض سلام و احترام
مقاله خدمت شما ارسال شد.
موفق باشید.
سلام
اول تشکر میکنم بخاطر مطالب مفید و غیر تکراری که منتشر میکنید،خسته نباشید
مقاله بسیار جامعی بود،اگر امکانش هست مقاله اصلی را برای بنده هم ارسال کنید، سپاسگزارم
با عرض سلام و احترام و همچنین تشکر بابت نظر شما
مقاله ارسال شد.
سلام، با تشکر از مطلب خوبی که گذاشتید ، بنده دانشجوی ارشد آمار هستم موضوع پایان نامه قصد دارم یادگیری ماشین کار کنم لطفا مقاله را به آدرس ایمیلم ارسال کنید و اگه راهنمایی برای من دارید ممنون میشم بگید. با تشکر.
با سلام و درود خدمت شما
مقاله ارسال شد
ممنون از مطلالب مفید و کاربردی لطفا در صورت امکان مقاله را برای من ایمیل کنید
با عرض سلام و احترام
مقاله ارسال شد
سلام خسته نباشید
اگه ممکنه مقاله این متن را برا منم بفرستید
با تشکر
با سلام و احترام
مقاله ارسال شد.
سلام خیلی ممنون از مطالب خوبتون اگر امکانش هست برای من هم مقاله رو ارسال کنید با تشکر
با سلام و تشکر از نظر لطف شما
مقاله ارسال شد.
با سلام و احترام و تشکر بابت مطالب خوبتون
لطفا مقاله رو برای من ارسال کنید.
با سلام و احترام فراوان
مقاله ارسال شد
سلام ممنون از مقاله مفیدتون در صورت امکان جهت مطالعه بیشتر برام ایمیل بفرمایید ممنون.
با عرض سلام و احترام
مقاله ارسال شد.
Hello, Thank you for your article about Machine Learning, please sent to me for more study.
با عرض سلام و احترام
ممنون بابت نظر لطف شما
مقاله ارسال شد
با سلام و خسته نباشید و ممنون از این مقاله عالی
اگر برای بنده هم ارسال بفرمایید که بتوانم از آن در پایان نامه ام با ذکر منبع استفاده کنم سپاسگزار خواهم بود
با عرض سلام و احترام خدمت شما و ممنون از نظر لطفتون
مقاله یادگیری ماشین (Machine learning) خدمت شما ارسال شد
ممنون از این مقاله خوبتون.
با عرض سلام و احترام فراوان
ممنون از نظر لطف شما
بسیار عالییییی بود. متشکرم
لطفا مقاله رو واسه من بفرستیم
با سلام و عرض ادب
ممنون از نظر شما
مقاله ارسال شد
با سلام
ممنون از اطلاعت خوبی که در اختیارمان قرار دادید. اگه براتون مقدوراست ممنون میشم مقاله را برای بنده نیز ارسال بفرماید.
با سلام و عرض ادب
ممنون از نظر شما
مقاله ارسال شد
با عرض سلام و ادب
سپاس از مقاله بسیار خوبتون
اگرممکن هست مقاله را برای بنده به منظور ذکر منبع در پایان نامه بفرستید.
با تشکر
با عرض سلام و احترام فراوان
مقاله به همراه منابع ارسال شد
با سلام ممنون از مقاله ی خوبتون من یک ارائه دارم در رابطه با همین موضوع اگر ممکن برام ارسال کنید باذکر منبع
با تشکر
با عرض سلام و احترام
از این تاریخ به بعد امکان کپی برداری از مقالات وب سایت برای کاربران عزیز فعال گردیده.
تمام سعی تیم تلاشگر مدیاسافت ارائه، ترجمه و نشر مقالات علمی کاملا رایگان برای ارتقا سطح دانش کشور و علاقمندان به حوزه علم و فناوری می باشد.
امیدوارم با درج نام وب سایت “مدیاسافت” به عنوان منبع اصلی ترجمه ی این مقالات در حفظ و رعایت حقوق ناشر و مترجم گام بردارید.
با تشکر از شما عزیزان
با سلام و عرض احترام
ممنون از اطلاعات مفیدی که در اختیار گذاشتید
در صورت امکان مقاله اصلی را با مراجع آن برای بنده ارسال نمایید
با سلام و احترام
و ممنون از نظر لطفتون
مقاله ارسال شد.
با سلام
عرض تشکر از مقاله بسیار خوبتان
لطفا برای اینجانب ایمیل نمایید
با سپاس
با سلام و درود خدمت شما
مقاله یادگیری ماشین ایمیل شد.
باسلام و عرض احترام و تشکر از مطالب بسیار خوبتان
لطفا درصورت امکان مقاله اصلی و منابع آن را جهت استفاده در پایان نامه برای بنده ارسال نمایید
سپاس از شما
با سلام و احترام و ممنون از نظر شما
مقاله ارسال شد به ایمیل شما
باسلام و ادب
ضمن تشکر از مطالب ارزشمند جنابعالی
چنانچه مقدور باشد ممنون خواهم شد مقاله را برایم ارسال فرمایید.
تشکر
با عرض سلام و احترام
از این تاریخ به بعد امکان کپی برداری از مقالات وب سایت برای کاربران عزیز فعال گردیده.
تمام سعی تیم تلاشگر مدیاسافت ارائه، ترجمه و نشر مقالات علمی کاملا رایگان برای ارتقا سطح دانش کشور و علاقمندان به حوزه علم و فناوری می باشد.
امیدوارم با ذکر نام وب سایت “مدیاسافت” به عنوان منبع اصلی ترجمه ی این مقالات در حفظ و رعایت حقوق ناشر و مترجم گام بردارید.
با تشکر از شما عزیزان
سلام خسته نباشید
ببخشید اگه امکانش هست مقاله رو هم برای بنده ارسال کنید
ممنون
با سلام و احترام
مقاله ارسال شد
سلام. وقت بخیر
ممنون از زحمتی که برای مطلب کشیدید
لطفا اصل مقاله رو برای من بفرستید
و بهتره در زیر مطلب هم فایل مقاله رو بزارید، تا کمتر زحمت بیفتید
ممنون
با عرض سلام و احترام و تشکر بابت نظر لطف شما؛
مقاله ارسال شد.
در این خصوص اتفافا چندین بار هم به دوستان عرض کردم که به زودی امکان دانلود مقالات برای کاربران محترم مدیاسافت فراهم خواهد شد.
با تشکر مجدد از شما.
با سلام و خسته نباشید
ممنون میشوم اگر مقاله را برای اینجانب ارسال فرمایید .
لطفا اگر در این زمینه مطالب دیگری نیز دارید برای بنده ارسال فرمایید.
با تشکر
با عرض سلام و احترام و تشکر بابت نظر لطف شما؛
مقاله ارسال شد.
در این زمینه مقالات زیادی در حال بررسی و ترجمه هستن که به زودی در وب سایت مدیاسافت منتشر خواهند شد.
همچنین شما میتونید لینک مطلب درخواستیتون رو داخل سایت قرار بدید و تیم ترجمه و تولید محتوای سایت مقالات درخواستی شما رو پس از بررسی ترجمه نمایند و در اختیار شما قرار دهند.
سلام خسته نباشید
ببخشید من مقاله برای بنده هنوز ارسال نشده
امکانش هست مجددا ارسال کنید
ممنون میشم
سلام خسته نباشید اگه امکانش هست مقاله رو برای من هم ارسال کنید
با عرض سلام و احترام و تشکر بابت نظر لطف شما؛
مقاله ارسال شد.
سلام ممنون از اطلاعات خوبتون
در صورت امکان مقاله مربوط را برای بنده هم ارسال نمایید .
باتشکر
نگار
با عرض سلام و احترام و تشکر بابت نظر لطف شما؛
مقاله ارسال شد.
سلام.خسته نباشید.مهندسی برق قدرت میخونم.تز ارشدمم میخوام رو بیگ دیتا ها کار کنم.ماشین لرنینگ خوبه که یاد بگیرم؟با تشکر
خسته نباشید
اگر امکان دارد مقاله لاتین اصل این اثر را برای بنده ارسال نمایید.
تشکر
با سلام و عرض احترام
مقاله ارسال شد
سلام سپاس از اطلاعات مفیدتون
در صورت امکان ممنون میشم مقاله ی فوق را برایم ارسال نمایید
باتشکر
با عرض سلام و احترام
از این تاریخ به بعد امکان کپی برداری از مقالات وب سایت برای کاربران عزیز فعال گردیده.
تمام سعی تیم تلاشگر مدیاسافت ارائه، ترجمه و نشر مقالات علمی کاملا رایگان برای ارتقا سطح دانش کشور و علاقمندان به حوزه علم و فناوری می باشد.
امیدوارم با ذکر نام وب سایت “مدیاسافت” به عنوان منبع اصلی ترجمه ی این مقالات در حفظ و رعایت حقوق ناشر و مترجم گام بردارید.
با تشکر از شما عزیزان
با سلام
اگه زحمتی نیست تعدادی مقاله خیلی خوب که مورد تایید این سایت می باشد و کارآمد در حوزه یادگیری ماشین اگر دارین برای بنده هم ارسال نمایید.
باتشکر
با عرض سلام و احترام
مقالاتی از جمله یادگیری عمیق در آینده ای نزدیک منتشر خواهد شد.
با سلام و خسته نباشید
خیلی ممنون از مطالب خوبتون
اگ امکانش هس برا منم این مقاله رو بفرستید..ممنون میشم
با عرض سلام و احترام فراوان
مقاله ارسال شد
سلام ممکنه این مطلب رو برام ارسال کنید؟ مطالب خیلی جذاب بود برای ارایه میخاستم.
با عرض سلام و احترام
از این تاریخ به بعد امکان کپی برداری از مقالات وب سایت برای کاربران عزیز فعال گردیده.
تمام سعی تیم تلاشگر مدیاسافت ارائه، ترجمه و نشر مقالات علمی کاملا رایگان برای ارتقا سطح دانش کشور و علاقمندان به حوزه علم و فناوری می باشد.
امیدوارم با درج نام وب سایت “مدیاسافت” به عنوان منبع اصلی ترجمه ی این مقالات در حفظ و رعایت حقوق ناشر و مترجم گام بردارید.
با تشکر از شما عزیزان
باسلام و آرزوی موفقیت
اگه امکانش هس مقاله ای رو باذکر منبع برام بفرستین…مطالبی برای پاورپونیت میخوام درمورد strong machine learning
با عرض سلام و احترام
از این تاریخ به بعد امکان کپی برداری از مقالات وب سایت برای کاربران عزیز فعال گردیده.
تمام سعی تیم تلاشگر مدیاسافت ارائه، ترجمه و نشر مقالات علمی کاملا رایگان برای ارتقا سطح دانش کشور و علاقمندان به حوزه علم و فناوری می باشد.
امیدوارم با ذکر نام وب سایت “مدیاسافت” به عنوان منبع اصلی ترجمه ی این مقالات در حفظ و رعایت حقوق ناشر و مترجم گام بردارید.
با تشکر از شما عزیزان
سلام لطفا برا منم بفرستین
مطالبی برای پاورپوینت در مورد Strong Machine Learning میخوام
مرسی
با عرض سلام و احترام
مقاله ارسال شد.
سلام
مطلب خیلی دقیق، روان و با جزئیات مفیدی بود. من از بخشی از آن در رساله ام استفاده کردم. ممنون میشم منابعش را برای بنده ارسال کنید.
با سلام. اگر امکان داره لطفا مقاله (مطالب درج شده بالا) را با ذکر منبع برای من ارسال بفرمایید.
با احترام
سلام
ممنون از مطالب مفیدتون
لطفاْ اگر امکانش هست اصل مقاله رو برام بفرستین
بازم ممنون
با سلام و عرض ادب
اگر امکان دارد مقاله لاتین اصل این اثر را برای بنده ارسال نمایید.
تشکر از لطفتان
با سلام لطفا مقاله برای من نیز ارسال شود.
باتشکر
سلام
تشکر میکنم بخاطر مطلب مفیدی که منتشر کردید.
اگر امکانش هست مقاله اصلی را برای بنده هم ارسال کنید،
سپاسگزارم
۳۸
با سلام و خسته نباشید
می توانید اصل مقاله برای اینجانب هم بفرستید
با تشکر
سلام لطفا مقاله برام ارسال کنید و چطور درسایت ثبت نام کنم ممنون
عرض سلام او حترام خدمت شما کاربر گرامی
برای ارسال مقاله خدمت شما نیاز به ثبت نام در وب سایت نیست
همچنین امکان کپی برداری از مقالات وب سایت فراهم گشته.
سلام
ممنون از مطالبتون
لطفا اگر امکانش هست اصل مقاله رو برام بفرستین
با تشکر
امکانش است مرجع این مطالب را بفرمایید؟
با عرض سلام و احترام
تعداد منابع این مقاله متعدد و کثیر هستش و امکان ارسال اونها از طریق ایمیل انجام پذیر خواهد بود.
باسلام و تشکر از مطالب بسیار مفید
درصورت امکان مقاله را برای من نیز ارسال نمایید
باتشکر
Thank you for your information. Please send me the full paper
سلام و وقت به خیر
اگر امکانش هست مقاله اصلی و مرجع این مطالب را برای بنده ارسال کنید،
سپاسگزارم
با سلام و احترام
لطفا در صورت امکان مقاله اصل این مطالب و مراجع را برای من ایمیل بفرمایید
متشکرم
با سلام و احترام
ممنون از مطالب خوبتون
در صورت امکان مقاله مربوط را برای بنده هم ارسال نمایید.
پریسا
لطفا این مقاله رو ارسال کنید
با سلام و تشکر از مطلب مفید و جالبتون
اگر امکانش هست مقاله رو برای بنده ارسال نمایید.
سپاس فراوان
با سلام.ممنون از توضیحات خوبتون.میشه این مقاله و منابعش رو به ایمیل من بفرستید.خیلی خیلی ممنونم
با عرض سلام و احترام فراوان و با تشکر از نظر لطف شما
مقاله ارسال شد
سلام. باتشکر از مطالب ارایه شده
آیا امکان ارسال این مقاله هست؟
با سلام و احترام
ممنون از مطالب مفیدتون واقعا خوب بود
اگر امکان داره مقاله را برای بنده ارسال نمایید با تشکر
با عرض سلام و احترام فراوان و با تشکر از نظر لطف شما
مقاله ارسال شد
سلام مجدد
اگر امکان دارد مقاله منبع یا لاتین رو برای بنده ارسال نمایید با تشکر
با سلام و احترام
مقاله ارسال شد
با سلام و احترام
لطفا اصل مقاله فارسی و منبع آن را برای بنده ارسال کنید
با تشکر
با عرض سلام و احترام فراوان
مقاله ارسال شد
باسلام
ممنون بابت مطالب
در صورت امکان مقاله ی این متن رو ارسال بفرمایید
با عرض سلام و احترام
مقاله ارسال شد
سلام من برای تحقیقم نیازفراونی ب این مقالتون دارم باید برای ارائه آماده شم اگر میشه برام سریع تر بفرستین این آدرس ایمیلمه ممنونمelare.roshan@yahoo.com
با سلام .ممنون از مطلب بسیار خوبتون. اگر امکان داره مقاله کامل رو برای من بفرستید .
با سلام و تشکر از زحمات ارزشمند شما
آقای ملازاده میخواستم ازتون خواهش کنم که لطف کنیدو فایل اصلی مقاله رو برای من ارسال کنید
با سپاس
سپیده
با عرض سلام و احترام
ممنون بابت مطالب
در صورت امکان مقاله ی این متن به همراه منابع رو ارسال بفرمایید
سلام. لطفا مقاله رو برای منم بفرستین.
سلام بسیار عالی بود
لطفا مقاله را برای بنده بفرستید
عرض سلام و احترام
مقاله ارسال شد
سلام
تشکر از مقاله خوبتون.اگر برای بنده هم ارسال کنید ممنونتون میشم.
باسلام و احترام
و ممنون بابت مطالب
اگر ممکن است مقاله را برایم ارسال کنید
ممنون
عرض سلام و احترام
مقاله ارسال شد
بسیار مقاله کامل و جامعی بود
برای ارائه این موضوع میخواستم اگر ممکن باشه مقاله رو برای من هم ارسال کنید
عرض سلام و احترام
مقاله ارسال شد
سلام لطفا مقاله رو برای من هم ارسال کنید . سپاسگزارم
عرض سلام و احترام
مقاله ارسال شد
با عرض سلام و وقت بخیر. لطفا اگر امکانش وجود دارد مقاله را برای بنده ارسال فرمایید. باتشکر
عرض سلام و احترام
مقاله ارسال شد
سلام ، ممنون از مطالبتون ، لطفا مقاله و منبع توضیحات را رو میشه برام ارسال کنید، و یه سوال ، اگر بخوام از مطالب استفاده کنم منبع باید چی بیارم دقیقا
ممنون
عرض سلام و احترام
مقاله به همراه منابع ارسال شد
سلام میشه لطف کنید مقاله را برامن ارسال کنید
ممنون میشم
عرض سلام و احترام
مقاله ارسال شد
سلام. لطفا مقاله رو برای منم بفرستین.
با عرض سلام و احترام
ارسال شد
باسلام وتشکر از مطالب مفیدتون.درصورت امکان اصل مقاله رو برای من ارسال کنید.
با عرض سلام و احترام
ارسال شد
با سلام و وقت بخیر
لطفا مقاله اصلی به همراه مراجع رو برای بنده ارسال بفرمایید
با تشکر
عرض سلام و ا حترام
مقاله ارسال شد